Menzerath-Altmann-Gesetz
Das Menzerath-Altmann-Gesetz ist ein auf Beobachtungen des Psychologen und Phonetikers Paul Menzerath basierendes Gesetz, welches die Beziehung zwischen der Größe eines sprachlichen Konstrukts und der Größe seiner Konstituenten beschreibt. Die zugrundeliegende Beobachtung weist auf den Zusammenhang zwischen Lautdauer und dem Lautganzen hin, wonach ein Laut dann kürzer gesprochen wird, wenn das Wort oder die Silbe in der er auftritt, länger bzw. lautreicher ist (vgl. Köhler, 2005: 659f). Dieses, bereits Ende des 19. Jahrhunderts untersuchte Phänomen, bezeichnet Menzerath als Quantitätsgesetz und formuliert die Hypothese einer Sparsamkeitsregel
- "Je größer das Ganze, um so kleiner die Teile!"
(Menzerath, 1954: 101)
Im Jahre 1980 formalisiert Gabriel Altmann - Sprachwissenschaftler und zu dieser Zeit Professor für mathematische Linguistik an der Ruhr-Universität Bochum - erstmals die Menzerath'schen Entdeckungen und entwickelt eine Reihe weiterer Hypothesen, die als Konsequenzen aus dem Menzerath'schen Gesetz hervorgehen.
Da das Menzerath'sche-Gesetz auf Ableitungen einer Differentialgleichung basiert, ist es nicht nur in der Lage die Beschreibung funktionaler Zusammenhänge zu liefern, sondern bietet auch eine Erklärung. Auf dieser Grundlage lassen sich weitere Hypothesen ableiten.
Contents
Menzeraths Studie
In seinen Studien zur Architektonik des deutschen Wortschatzes unternimmt Paul Menzerath den Versuch, die deutschen Worttypen zu suchen und ihre Verteilung sowie ihre Häufigkeit zahlenmäßig zu bestimmen und darzustellen. Dazu möchte er wissen, in welcher Ausdehnung (Häufigkeit, Belastung, Dichte) die einzelnen Formtypen vorkommen, d.h. welche Arten "`typisch"' (charakteristisch) sind und welche weniger, kaum oder garnicht vorkommen (Menzerath, 1954: 1f).
Untersuchungsgegenstand sind 20 453 Wörter (unter der Annahme eines Totalkollektivs von 500 000) (Menzerath, 1954: 4f). Die Grundlage der Untersuchungen bildet das "Deutsche Aussprachewörterbuch" von Viëtor und Meyer (1921).
Die Einteilung bei den zugrundeliegenden Kriterien (Silben- und Lautzahl sowie Lautfolge) bildet sich wie folgt:
- Worttypen: nach Maßgabe der Silbenzahl
- (Einsilber, Zweisilber, Dreisilber usw.).
- Klassen (Variationen innerhalb eines Worttyps): verschiedene Lautzahl
- (Einlauter, Zweilauter, Dreilauter usw.).
- Gruppe/Formtyp: Anordnung (Reihenfolge) der Laute innerhalb der Klasse.
Zum Beispiel sind als, das und froh allesamt Einsilber und zwar Einsilber der Klasse 3 (Dreilauter), sie unterschieden sich jedoch charakteristisch und unverwechselbar durch die Position des Silbengipfels, der bei als am Anfang, bei das in der Mitte und bei froh am Ende liegt. Somit gehören alle drei unterschiedlichen Formtypen an.
Auf diese Weise lässt sich der gesamte Wortbestand vollständig aufteilen und zergliedern. Die "`Belastung"' (Schwere, Häufigkeit, Dichte) des jeweiligen Worttyps bzw. der Klasse und der Gruppe entspricht der Anzahl aller jeweils unter die betreffende Zählkategorie fallenden Beispiele (Menzerath, 1954: 7).
Menzeraths Entdeckung
Die gesamten Beobachtungen fasst Menzerath in Tabelle 1 zusammen. Auf den ersten Blick sieht man schon, dass ein Zusammenhang zwischen Silben- und Lautzahl besteht. Bei jedem einzelnen Worttyp lässt sich feststellen, dass die Häufigkeiten in Abhängigkeit von der Lautzahl stets eine glockenförmige Verteilungskurve (Polygon) zeigen. Die neue Erkenntnis ist, dass bei der Anordnung nach konstanter Lautzahl (waagerechte Zeile) ebenso jedesmal ein bevorzugter Wert auftritt (hier fett gedruckt), und zwar eine Silbenzahl. Das bedeutet, dass die Häufigkeitsverteilung sowohl in waagerechter Richtung (konstante Lautzahl), als auch in senkrechter Richtung (konstante Silbenzahl) Glockenform hat.
Das gleiche gilt für die Häufigkeitssummen (unterste Zeile und letzte rechte Spalte). Bis auf die schwach belegten drei letzten Worttypen gibt es in dieser Tabelle keine einzige wirkliche Unregelmäßigkeit, sondern unveränderliche richtungstreue, zu- oder abnehmende, Zahlenwerte. Dies verdeutlicht nicht nur die Architektonik des Gesamtwortschatzes, sondern auch dessen "innere Struktur".
Am häufigsten von allen deutschen Worttypen ist das Dreisilbenwort: es umfasst gut ein Drittel der Gesamtzahl. Ihm folgt in geringem Abstand der Zweisilber. Der Viersilber schließt sich in weitem Abstand an, er umfasst nur noch etwa ein Sechtel. Erst an vierter Stelle steht - mit etwa einem Neuntel der Gesamtzahl - der Einsilber. Der Fünfsilber erreicht nicht einmal ein Zwanzigstel. Verschwindend gering sind die Anteile der Sechs- bis Neunsilber.
Zwei-, Drei- und Viersilber zusammen ergeben 82,3 \% des gesamten deutschen Wortschatzes (Menzerath, 1954: 97).
Bisher wurde nur die absolute Häufigkeit, eine Funktion zwischen den zwei Veränderlichen z (Silbenzahl) und n (Lautzahl), betrachtet. Die relative Häufigkeit, das Verhältnis der Teile eines Kollektivs zur Gesamtheit dieses Kollektivs, ist jedoch von noch größerer Bedeutung. Tabelle 2 beinhaltet diese relativen Werte und weist alle erfassten Wortgruppen auf. Das dabei entstehende Häufigkeitsgebirge ist in Abbildung 1 dargestellt. Es ist ersichtlich, dass sie sich allesamt um die Diagonale herum gruppieren (Menzerath, 1954: 98).
Silbenzahl und Lautzahl stehen offenbar in einem gesetzmäßigen Verhältnis zueinander. Beim Vergleich der beiden Reihen (auf Tabelle 1) drängen sich zwei auffallende Beobachtungen in den Vordergrund:
- "Die relative Lautzahl nimmt mit steigender Silbenzahl ab, oder mit anderer Formel gesagt: je mehr Silben ein Wort hat, um so (relativ) kürzer (lautärmer) ist es."
(Menzerath, 1954: 100)
Einsilbige Wörter umfassen 1 - 7 Laute, Zweisilber 2 - 10 Laute, Dreisilber 4 - 14 (nur doppelt soviel Laute wie das längste einsilbige Wort), Viersilber 6 - 16 Laute, Fünfsilber 7 - 17 Laute, Sechssilber 10 - 20 Laute, Siebensilber 13 - 21 Laute (das längste siebensilbige Wort besitzt nur dreimal soviel Laute wie das längste einsilbige Wort), Achtsilber 16 - 21 Laute und Neunsilber 18 - 22 Laute.
- "Je silbenreicher die Wörter sind, um so geringer wird die Schwankungsbreite der Elementenzahl. Viersilbige Wörter sind also in der Lautzahl untereinander ziemlich gleich, während die geringsilbigen Wörter stärker schwanken."
(Menzerath, 1954: 102)
Einsilber umfassen 1-7 Laute, d.h. 7-fache Variation (das längste Einsilbenwort hat siebenmal soviel Laute wie das kürzeste). Zweisilber umfassen 2 - 10 Laute (5-fache Variation), Dreisilber 4 - 14 Laute (3,5-fache Variation), Viersilber 6 - 16 Laute (2,7-fache Variation), Fünfsilber 7 - 17 Laute (2,4-fache Variation), Sechssilber 10 - 20 Laute (2-fache Variation, d.h. der längste Sechssilber hat nur doppelt soviele Laute wie der kürzeste), Siebensilber 13 - 21 (1,6-fache Variation), Achtsilber 16 - 21 (1,3-fache Variation) und Neunsilber umfassen 18 - 22 Laute, d.h. nur 1,2-fache Variation.
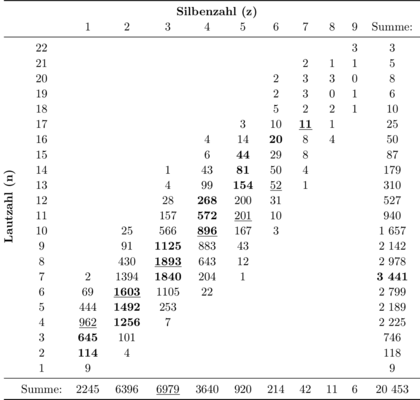
Tab. 1: Worttypen, Lautzahl und Häufigkeit, z=Silbenzahl, n=Lautzahl (Menzerath, 1954: 96).
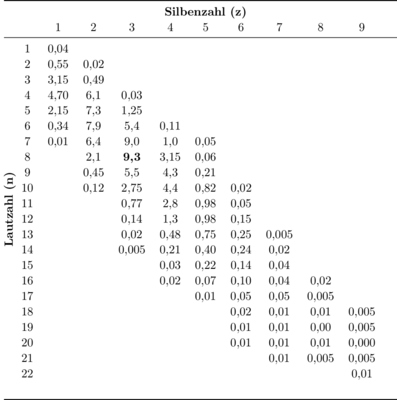
Tab. 2: Relative Häufigkeiten der deutschen Wortgruppen in % (Menzerath, 1954: 99).
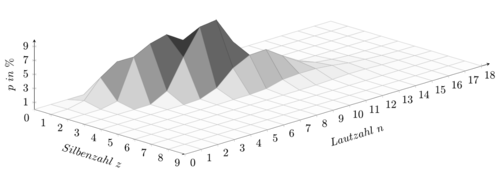
Abb. 1: Typenhäufigkeitsgebirge des deutschen Wortschatzes mit der relativen Häufigkeit p in % (Menzerath, 1954: 100)).

Zusammenfassung der Ergebnisse
Hinsichtlich der Ergebnisse, die er in der folgenden Auflistung zusammenfasst, formuliert Menzerath den Wunsch einer mathematischen Formalisierung:
- Der Wortbestand ist nicht beliebig verteilt, sondern systematisch geordnet (Normalverteilung).
- Das häufigste Wort im Deutschen ist das siebenlautige (beim Einsilber das vierlautige).
- Das häufigste Wort im Deutschen ist außerdem dreisilbig.
- Beim Einsilber werden die Grenzvokale (a, i, u) bei weitem bevorzugt.
- Mit steigender Silbenzahl nimmt die relative Lautzahl ab (oder: mit steigender Silbenzahl werden die Wörter relativ lautärmer (kürzer)).
- Mit steigender Silbenzahl nimmt die Zahl der Konsonanten ab. Die oben festgestellte Verringerung der Lautzahl geht auf Kosten der Konsonanten (jede Silbe fordert einen Vokal und kann sich damit begnügen).
- Mit steigender Silbenzahl nimmt auch die Schwankungsbreite der Elementenzahl ab (oder: mit steigender Silbenzahl werden die Lautzahlen mehr und mehr gleich).
- Das Gesamtverhältnis der Vokale zu den Konsonanten beträgt für das Deutsche etwa 1 : 1,5, d.h. auf einen Vokal kommen 1,5 Konsonanten.
Formalisierung durch Altmann
Auf Grundlage der Beobachtungen Menzeraths veröffentlicht Gabriel Altmann 1980 eine mathematische Form, die er das Menzerath'sche-Gesetz nennt. Die Grundlage bildet eine an die linguistische Terminologie angelehnte, etwas spezifischere Formulierung der Menzerath'schen Hypothese.
- "Je größer ein sprachliches Konstrukt, desto kleiner seine Komponenten (Konstituenten)."
(Altmann, 1980: 1)
"Größer" bedeutet in diesem Sinne "komplexer", also aus mehr Entitäten bestehend, "kleiner" bedeutet "einfacher", d.h. aus weniger Entitäten bestehend. Entität steht nicht notwendigerweise für einen materiellen Teil, es kann auch eine Funktion, Relation, Bedeutung etc. sein.
Die einfachste mathematische Formulierung dieser Aussage besteht in der Annahme einer konstanten Abnahmerate der Komponentenlänge
<math> (1) \qquad \frac{y'}{y}=-c. </math>
Bei Betrachtung der Kürzung proportional zur Länge (<math>y'=-cy</math>) ergibt sich durch Integration
<math> (2) \qquad ln~y = -cx + a </math> bzw. vereinfacht <math> y=a e^{-cx}. </math>
d.h. die Länge der Komponente (<math>y</math>) ist eine monoton fallende Funktion der Länge des Konstrukts (<math>x</math>).
Da davon auszugehen ist, dass die Kurve einiger Konstrukt-Komponenten Abhängigkeiten nicht monoton fallend ist, kann der Differentialgleichung (1) zur Verfeinerung (zusätzlich zur konstanten Abnahme <math>-c</math>) ein weiteres Glied <math>\tfrac{b}{x}</math> hinzugefügt werden, welches eine umgekehrt proportionale Abnahmerate <math>(\tfrac{y'}{y} \sim \tfrac{1}{x})</math> zur Konstruktgröße (<math>x</math>) mit einbezieht:
<math> (3) \qquad \frac{y'}{y} = -c +\frac{b}{x}. </math>
Die Hypothese kann nun neu formuliert werden in:
- "Die Größe der Komponenten ist eine Funktion der Größe sprachlicher Konstrukte."
(Altmann, 1980)
Diese Funktion ist durch Lösen der Differentialgleichung (3) gegeben. Je nachdem wie die Parameter <math>b</math> und <math>c</math> bestimmt sind, erhalten wir die folgenden Funktionen:
<math> \begin{align} (4)\qquad b& =0 & & & \qquad y& =ae^{-cx}\\ (5)\qquad b& \neq 0& c& = 0& \qquad y& = ax^b\\ (6)\qquad b& \neq 0& c& \neq 0& \qquad y& = ax^b e^{-cx}. \end{align} </math>
Die durch Funktion (5) entstehende Kurve ist für <math>b > 1</math> konvex steigend, für <math> 0 < b < 1 </math> konkav steigend und für <math> b < 0 </math> konvex fallend.
Die aus Funktion (6) resultierende Kurve ist nur dort monoton fallend, wo <math>\tfrac{-b}{c} > x </math> ist, d.h. die Kurve kann in bestimmten Bereichen steigen.
Die Parameter <math>a</math>, <math>b</math> und <math>c</math> sind in allen Fällen Konstanten, die für verschiedene Sprachen, auf unterschiedlichen Analyseebenen und abhängig vom Text (Stil, Genre etc.) verschiedenartige Werte annehmen können.
Berechnung und Interpretation
Berechnung der Parameter
Da über die Parameter der Kurven theoretisch nichts bekannt ist, müssen diese zunächst aus den Daten geschätzt werden. Ein weiteres Problem besteht in der Überprüfung der Frage, ob signifikante Unterschiede zwischen den Daten und der daraus abgeleiteten Kurve bestehen.
Die Berechnung der Parameter der Funktion erfolgt vorwiegend mit der Methode der kleinsten Quadrate. Die Parameter <math>a</math> und <math>b</math> sollen so bestimmt werden, dass die Summe der Abweichungsquadrate (<math>Q</math>) der beobachteten Werte von den berechneten Werten minimal ist, d.h. wir minimieren
<math> (7) \qquad Q = \sum_{i=1}^k n_i (Y_i - a - bZ_i)^2 </math>
wobei <math>n_i</math> die "Gewichte" sind, d.h. die Anzahl der beobachteten Entitäten, und <math>k</math> der höchste beobachtete Wert von <math>x_i</math>.
Die Güte der Anpassung wird mit dem F-Test überprüft. Eine ausführliche Beschreibung beider Verfahren findet sich in Altmann u.a. (1989: 15 - 21).
Interpretation der Parameter a, b und c
Nach der Aufstellung funktionaler Beziehungen besteht eine elementare Aufgabe darin, die Parameter der Funktion(en) allgemein zu bestimmen, bzw. die Parameter linguistisch zu interpretieren.
Durch Einsetzen der Konstruktlänge 1 (<math> x = 1</math>) in Formel (5) kann <math>a</math> direkt interpretiert werden:
<math> (8) \qquad y = a \cdot 1^b = a. </math>
Der Parameter <math>a</math> steht folglich für die durchschnittliche Länge eines Konstrukts, das aus einer einzigen Komponente besteht und dementsprechend für die Länge, die der Kürzungstendenz unterliegt.
Auf Satzebene bezogen ist <math>a</math> die mittlere Teilsatzlänge in Sätzen mit nur einem Teilsatz. Bei ansteigender Anzahl der Teilsätze wird die Teilsatzlänge verringert (vgl. Köhler 1982). Die numerische Größe von <math>a</math> ist sprach- und textspezifisch (vgl. Altmann, 1989). Sie ist in jedem Fall ebenenspezifisch.
Parameter <math>b</math> beschreibt die Steilheit der Kürzung. Er bemisst den Umfang an Strukturinformation, der durchschnittlich für ein Konstrukt mit einer Komponente erforderlich ist (vgl. Altmann, 1989 und Köhler, 1982). Er muss als empirische Konstante angesehen werden und ist demnach ebenfalls sprach- und eventuell textspezifisch, sowie in hohem Maße ebenenspezifisch (Köhler, 1982).
Parameter <math>c</math> wurde von Altmann u.a. (1989) als zusätzliche Störgröße eingeführt, bzw. als Glied, welches den Zuwachs repräsentiert (im Fall von Kürzung <math>-c</math>) und das Glied <math>\tfrac{b}{x}</math> als demjenigen Teil der Differentialgleichung (3), der eventuelle entgegengesetzte Einflüsse erfasst.
Eine allgemein anerkannte Zuordnung der Parameter und die Bestätigung vorhandener Annahmen durch Untersuchungen auf anderen linguistischen Ebenen stehen noch aus.
Auswahl der passenden Formel
Neben der Überprüfung des Menzerath'schen-Gesetzes auf Satzebene widmet sich Köhler (1982) der Frage, ob sich die Anzahl der interpretationsbedürftigen Parameter verringern lässt, indem eine der Formeln (4) oder (5) der allgemeinen Gleichung (6) vorgezogen wird.
Anhand von 4 englischen Texten wird Hypothese 5 überprüft. Die Satzlänge wird dabei in Teilsätzen (als Kriterium ist das Vorhandensein eines finiten Verbs gewählt), die Teilsatzlänge in Wörtern gemessen. Obwohl die Verwendung von Funktion (5) angemessen scheint (da auf Satzebene keine Nulllängen vorkommen und zudem von einer Kürzung bei zunehmender Satzlänge ausgegangen werden kann, d.h. <math>\scriptstyle b < 0</math>), werden auch die Funktionen (4) und (6) überprüft. Die Ergebnisse bestätigen Hypothese 5 sowie die Vermutung, dass die allgemeine Gleichung (6) gegenüber Funktion (5) keine deutlichen Verbesserungen bringt. Dieselbe Untersuchung mit einer Abänderung der Teilsatzkriterien (neben den finiten Verben werden auch Partizipien mit Objekt und Präpositionalphrasen als Teilsatzindikator gewertet) führt zu der gleichen Erkenntnis (Köhler, 1982).
Weiterhin kann angenommen werden, dass die Funktionen (4), (5) und (6) nicht mehr in dieser Form gelten, wenn (linguistische) Ebenen übersprungen werden. Die noch folgende Untersuchung von Hypothese 1 aus Geršić und Altmann (1980), in welcher die Abhängigkeit der mittleren Lautdauer (in Millisekunden) von der Wortlänge (in Lautanzahl) ohne Berücksichtigung der Silbe gemessen wird, kann als solches Beispiel gesehen werden.
Altmanns Hypothesen
Die folgenden Hypothesen ergeben sich als Konsequenzen auf Grundlage der Formalisierung der Menzerath'schen Hypothese:
- Hypothese 1: Mit zunehmender Wortlänge nimmt die Lautdauer ab.
- Störfaktoren können die Satzlänge, die Position des Wortes im Satz und die Wortart sein.
- (1a) Die Lautveränderung ist in längeren Wörtern häufiger als in kürzeren.
- Diachronische Konsequenz der ersten Hypothese. Wenn Laute in längeren Wörtern einer höheren Kürzungstendenz unterliegen, müssten sie auch eine höhere Veränderungstendenz aufweisen.
- (1b) Sprachstabilität
- Sprachen mit einer größeren mittleren Wortlänge erfahren im selben Zeitraum mehr phonetische/phonologische Veränderungen als Sprachen mit einer kleineren mittleren Wortlänge.
- Hypothese 2: Je länger das Wort, desto kürzer ist die Silbenlänge
- Entweder durch zwangsläufige Verkürzung der Silbendauer durch Lautverkürzung (Hypothese 1), oder durch Reduktion der Laut- bzw. Phonemzahl in der Silbe.
- (2a) Konsonantenreduktion
- Durch Hinzufügen eines Affixes zu einem Wort wird die Anzahl der Laute (vorwiegend der Konsonanten) reduziert.
- (z.B. Assimilation, Sandhi, Kontraktion, Kontamination, Konsonantenschwund etc.)
- (2b) Vokalepenthese
- Die Verkürzung findet wie bei (2a), jedoch durch Vokalepenthese bei Affixation oder bei Komposition statt. Durch die Epenthese wächst zwar das Wort um eine Silbe an, da die Silbe aber meist die minimale Länge aufweist, nimmt die durchschnittliche Silbenlänge im Wort ab.
- Hypothese 3: Morphemverkürzung
- Mit zunehmender Wortlänge nimmt auch die Morphemlänge ab.
- (3a) Bildung von Komposita
- Kurze Morpheme bilden mehr Komposita als lange, d.h., je länger eine bedeutungstragende Einheit ist, desto seltener ist ihre Verwendung bei der Wortzusammensetzung oder Ableitung.
- (3b) Verkürzung der Wurzel
- Je mehr Elemente (Wurzeln) ein Kompositum bilden, desto kürzer sind sie.
- (3c) partielle Reduplikation
- In natürlichen Sprachen ist partielle Reduplikation häufiger als volle Reduplikation, d.h., bei der Wortverlängerung wird vorzugsweise ein Konsonant eliminiert werden.
- Hypothese 4: Je länger die Phrase, desto kürzer die Wörter
- Diese Hypothese ist stark Störanfällig, da Textfaktoren (Genre, Stil, Fachtermini etc.) eine entscheidende Rolle spielen. Gerade diese Sensibilität birgt jedoch die Hoffnung, mit Hilfe des Funktionsverlaufs des Menzerathschen-Gesetzes Rückschlüsse auf Stil, Genre etc. zu ermöglichen.
- Hypothese 5: Je länger der Satz, desto kürzer die Teilsätze (Clauses)
- Zusätzlich zu den Ökonomie- und Redundanzargumenten der vorherigen Hypothesen kommt hier ein Verständlichkeitsproblem ins Spiel. Ein Satz aus vielen Teilsätzen (mit finitem Verb) verliert an Überschaubarkeit und Verständlichkeit. Je kürzer also die Teilsätze in langen Satzgebilden sind, desto klarer wird die Zusammengehörigkeit. Auf dieser Ebene ist, durch die hervorgehobene Rolle des Hauptsatzes sowie die verschiedenen syntaktischen Funktionen der Teilsätze, ebenfalls mit Störungen zu rechnen. Der Einfluss des Stils, des Genres etc. auf die Parameter ist auf dieser Ebene besonders ersichtlich.
- (5a) Je kürzer der Teilsatz, desto länger sind die Wörter die er enthält
- Konsequenz aus bisherigen Annahmen und Hypothese (5).
- Hypothese 6: Je länger der Satz, d.h. je kürzer die Teilsätze, desto länger die Wörter (Arens'sche Regel)
- Diese Hypothese ist eine Verbindung der Hypothesen (5) und (5a), die sehr gut verdeutlicht, warum bei der Untersuchung keine Ebenen übersprungen werden dürfen. Entfernt man nämlich den mittleren Teilsatz erhält man die Aussage: je länger der Satz, desto länger die Wörter, was in direktem Widerspruch zum Menzerath'schen-Gesetz steht.
- Hypothese 7: Gültigkeit auf textueller Ebene
- Diese Hypothese ist nur schwer zu formulieren, da der Satz: je länger der Text, desto kürzer sind seine Sätze, ohne die an dieser Stelle notwendig erscheinende genauere Definition eines Textes, wenig Sinn ergibt. Vielmehr kann, da der Text selbst nicht als Konstrukt in Frage kommt, von einer kleineren Einheit dem Textabschnitt ausgegangen werden.
- Hypothese 8: Je kürzer das Wort, desto größer ist die Bedeutungsmenge
- Dementsprechend sollten auch Wörter die eine geringere Bedeutungsmenge aufweisen länger sein. Somit kann entweder die Bedeutungsanzahl oder die Wortlänge als unabhängige Variable angesehen werden.
Neben den von Altmann ursprünglich formulierten Hypothesen (1) bis (6) können noch einige weitere hinzugefügt werden, so sind beispielsweise Nachforschungen im Bereich der Semantik denkbar, wenn auch durch methodische Schwierigkeiten wie der Realisierbarkeit der Bedeutungsermittlung kompliziert. Weiterhin wurde das Menzerath'sche-Gesetz im Rahmen empirischer Untersuchungen auch auf eine Vielzahl an Bereichen außerhalb der Linguistik übertragen.
Empirische Arbeiten zur Validität der Hypothesen
Viele der aus dem Menzerath'schen-Gesetz hervorgehenden Hypothesen sind durch zahlreiche Studien mit größtenteils hochsignifikanten Ergebnissen belegt. Allerdings wurde das Gesetz nicht in allen Bereichen im gleichen Ausmaß getestet. Die Allgemeingültigkeit des Menzerath'schen-Gesetzes ermöglicht zwar keinen endgültigen Nachweis der Hypothese, dennoch festigt jeder begünstigende Fall den Grad der Bestätigung (vgl. Altmann, 1980)
Die vorgenommenen Studien untersuchen ein breites Spektrum von Sprachen, Sprachebenen, Textsorten sowie Sprech- bzw. Produktionssituationen. Sie sind in der Lage, eine Vorstellung davon zu vermitteln, welche Vorgehensweisen bei den Untersuchungen gewählt wurden und geben Aufschluss über entstehende Fragen und Probleme. Im Folgenden wird eine Auswahl dieser Studien exemplarisch vorgestellt.
Hypothese 1 - Wortlänge und Lautdauer
Geršić und Altmann (1980) verfolgen in ihrer Arbeit die Frage, ob zwischen Lautdauer und Wortlänge des Batscha-Dialekts des Deutschen eine Abhängigkeit besteht, die dem Menzerath'schen-Gesetz folgt. Aus einem Datensatz von 488 Wörtern aus gesprochenen Texten ermitteln sie mit Hilfe instrumentalphonetischer Methoden die Lautdauer (in Millisekunden) und untersuchen ihre Abhängigkeit von der Wortlänge (gemessen in Lautzahl). Mehr als einmal im Datensatz vorhandene Wörter werden über das arithmetische Mittel ihrer Lautdauer erfasst. Die Auswertung erfolgt anhand der Mittelwerte, da lediglich die durchschnittliche Veränderung der Lautdauer in Abhängigkeit von der Wortlänge ermittelt werden soll.
Das Ergebnis ist in Abbildung 2 zu sehen. Die Punkte entsprechen den empirischen (gemittelten) Werten, die Linien beschreiben den Verlauf der berechneten Werte der Lautdauer. Den Bruch im Verlauf (zwischen <math>L_2 = 5</math> und <math>L_2 = 6</math>) interpretieren Geršić und Altmann entweder als unbekannten Faktor, der eine auffällige Dauerreduktion bei den Längen <math>L_2 = 2, 3, 4, 5</math> hervorruft oder als einen Faktor, der die Dauer aller Wörter der Länge <math>L_2 \geq 6</math> proportional vergrößert. Die Beobachtung, dass Wörter der Länge <math>L_2 \geq 6</math> (bis auf eine einzige Ausnahme) im untersuchten Material nie am Satzanfang vorkommen, weist auf einen Einfluss der Position des Wortes im Satz hin.
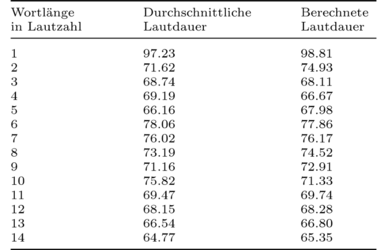
Tab. 3: Wortlänge bezüglich Lautdauer gemessen in Millisekunden (nach Geršić und Altmann (1980)).

Abb. 2: Lautdauer L1 in Wortlänge L2 für den Batscha-Dialekt des Deutschen (nach Geršić und Altmann (1980: 119)).
Der Bruch des Verlaufs zwischen <math>L_2 = 5</math> und <math>L_2 = 6</math> erlaubt es, den Verlauf in zwei Teilen zu erfassen. So kann für den ersten Teil <math>a = 1</math> und für den Zweiten <math>b = 0</math> gesetzt werden. Die genutzten Formeln sind somit Formel (6) für den ersten Abschnitt und für den zweiten Bereich Formel (4).
Auf Grundlage der empirischen Daten lassen sich die Parameter der Funktion errechnen:
<math> \begin{align} y& = 84,20x^{-0,63}e^{0,16x} & \qquad \mbox{für} \quad x& = 1, 2,..., 5 \\ y& = 88,78e^{-0,021881x} & \qquad \mbox{für} \quad x& = 6, 7,..., 14 \end{align} </math>
Trotz einer relativ großen Übereinstimmung zwischen den empirischen Werten und den Kurvenverläufen ist das Ergebnis nicht restlos überzeugend, was möglicherweise mit der übersprungenen Ebene einhergeht, da Laute statt Silben als direkte Konstituenten der Wörter betrachtet werden. Dennoch kann in dieser Studie eine Bestätigung für Hypothese 1 gesehen werden (Köhler, 2005).
Hypothese 8 - Bedeutungskomplexität
Unter der Annahme, dass mit der Vergößerung der Länge des Wortes seine Bedeutung spezifiziert wird und daher seine Bedeutungskomplexität abnimmt, untersuchen Fickermann u.a. (1984) die Beziehung zwischen Wortlänge und Bedeutungskomplexität der Wörter für das Englische.
Grundlage der Daten bildet eine systematische Stichprobenerhebung aus einem Lexikon. Die Auszählung umfasst 1130 Wörter, wobei das jeweils letzte Wort einer Seite verwendet wird (sofern es sich nicht um Eigennamen, Abkürzungen oder Wortverweise handelt).
Aufgrund hoch signifikanter Ergebnisse vorhergehender Studien zur Bedeutungskomplexität anderer Sprachen, entscheiden sie sich für die Verwendung von Funktion (5). Die Koeffizienten der Kurve <math>y=ax^b</math> werden nach logarithmischer Transformation mit der Methode der kleinsten Quadrate geschätzt und die Anpassung mit dem F-Test überprüft. Die Rechnungen ergeben:
<math> y = 33,2142x^{-1,3556}; ~F(1,9) = 151,82; ~P = 0,0000006.</math>
Die Untersuchung bekräftigt die Gültigkeit des Menzerath'schen-Gesetzes auf semantischer Ebene.
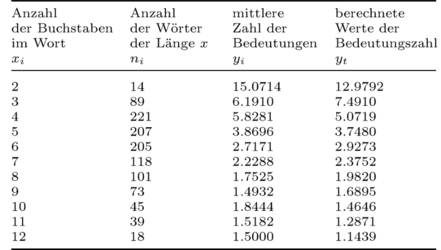
Tab. 4: Mittlere Bedeutungslänge nach Buchstabenlänge im Englischen (nach Fickermann u.a. (1984)).
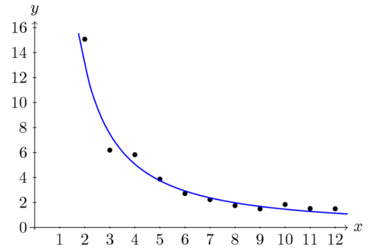
Abb. 3: Beziehung zwischen der Länge eines Wortes in Buchstaben (<math>x</math>) und der Bedeutungsanzahl (<math>y</math>) (nach Fickermann u.a. (1984)).
Hypothese 2 - Wortlänge und Silbenlänge
Eine weitere von Altmann u.a. (1989) zitierte Studie beschäftigt sich mit der durchschnittlichen Silbenlänge für das amerikanische Englisch. Die durchschnittliche Silbenlänge (gemessen in Phonemen) wird auf Grundlage von 10064 ausgewerteten Wörtern bestimmt. Die Ergebnisse sind in Tabelle 5 wiedergegeben. Nach der Berechnung der Parameter <math>a</math> und <math>b</math> auf Grundlage der Daten ergibt sich mit Formel (5) folgende Funktion:
<math>y = 4,0852 x^{-0,3578}</math>
Ein Vergleich zwischen empirischen und berechneten Werten zeigt eine sehr gute Übereinstimmung. Weitere Untersuchungen mit vergleichbaren Messdaten weisen für unterschiedliche Sprachen (Deutsch, Italienisch, Serbokroatisch und Indonesisch) ebenfalls signifikante Ergebnisse der Anpassungen auf, welche die Gültigkeit des Menzerath'schen-Gesetzes auch in diesem Bereich bestätigen.
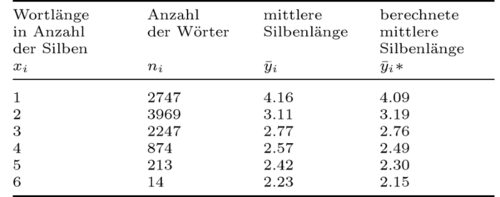
Tab. 5: Mittlere Silbenlänge im amerikanischen Englisch (nach Altmann u.a. (1989)).
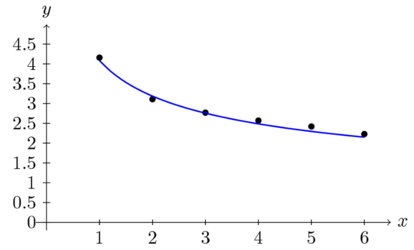
Abb. 3: Beziehung zwischen Wortlänge in Silben (<math>x</math>) und Silbenlänge in Phonemen (<math>y</math>) (nach Altmann u.a. (1989)).
Das Menzerath-Altmann-Gesetz außerhalb der Linguistik
Die Gültigkeit des Menzerath-Altmann-Gesetzes hat sich in vielen Untersuchungen auf einer Vielzahl sprachlicher Ebenen und verschiedener Sprachen gezeigt. Über die Linguistik hinaus kann das Gesetz aber auch zur Beschreibung verschiedener Zusammenhänge (z.B. in der Musik, DNA-Forschung, Soziologie, Psychologie uvm.) genutzt werden.
Strukturmerkmale von Primatensozietäten
Studien zeigen beispielsweise, dass die Größe sozialer Einheiten von Pavianen mit steigender Populationsgröße sinkt. Die biologische Bedeutung dieser Regelhaftigkeit kann in der Erzeugung maximaler Nachkommenszahlen gesehen werden, da mit steigender Größe der sozialen Einheit (in einem von allen Mitgliedern geteilten Areal) tendenziell Probleme in der Ressourcen-Nutzung auftreten, welche die soziale Ordnung destabilisieren (vgl. Altmann u.a., 1989).
Als Modell der psychischen Informationsverarbeitung
Ein ähnlicher Effekt kann in der organismischen Informationsverarbeitung beobachtet werden. Ausgehend von der Annahme, dass die Informationsverarbeitung verbaler Inhalte im Zentralnervensystem seriell erfolgt und die Informationsfülle demnach an die begrenzte Kapazität des Kurzzeitgedächtnisses angepasst werden muss, untersucht Schwibbe in Altmann u.a. (1989) die Beziehung zwischen dem Niveau der Informationsverarbeitung und dem Menzerath'schen-Gesetz.
Ein Vergleich der Beziehung zwischen Satzlänge (in Teilsätzen) und Teilsatzlänge (in Wörtern) zwischen normalen Briefen von Privatpersonen (mit neutraler Aktivationslage) und Briefen suizidaler Personen (unter extremem Stress) zeigt, dass unter hoher Aktivation des Organismus bei zunehmender Konstruktgröße eine zu verarbeitende sprachliche Einheit in ihrer Größe eher reduziert wird als in einem ausgeglichenen Aktivationszustand. Die Verkürzung dient der Sicherung der Informationsübertragung, welche durch das Senden kürzerer, leicht überprüfbarer Informationseinheiten gesichert werden soll. Prinzipiell lässt sich dieses Modell auf alle Systeme übertragen, die in einem kommunikativen Prozess miteinander stehen.
Mithilfe dieser Erkenntnis ist eine bessere Beschreibung und Erklärung von Sprach- und Gedächtnisfunktionen, sowie die Analyse von Störungen der Gedächtnis- und Verarbeitungsprozesse möglich.
Untersuchungen der DNA-Forschung
Auf Ebene der genetischen Informationsübertragung widmen sich Wilde und Schwibbe in Altmann u.a. (1989) der Frage, ob die Größe des Konstrukts mit der Größe der Konstituenten in Zusammenhang steht. Zum einen wird dabei die DNA, in welcher die genetische Information einer Zelle gespeichert ist, als Konstrukt angesehen, das aus verschiedenen Konstituenten z.B. Chromosomen besteht. Zum anderen wird die DNA selbst als Konstituente der morphologischen Spezifikation betrachtet.
Es lässt sich feststellen, dass umso größer die DNA (gemessen in Anzahl der Chromosomen) ist, die Chromosomen (gemessen in mm) kleiner werden. Für den Spezialisierungsgrad einer Spezies lässt sich erkennen: je größer der Grad an Spezialisierung einer Art ist, desto kleiner ist deren DNA.
In der Musik
Ausgehend von der Ähnlichkeit der beiden Systeme Musik und Sprache untersuchen Boroda und Altmann (1991) die Validität des Menzerath'schen Gesetzes in der Musik. Dabei wird die hierarchische Ordnung einer Komposition als eines der leitenden Grundprinzipien, und die Länge einer Einheit als wichtige Charakteristik angesehen. Untersuchungen in diesem Gebiet werden allerdings durch die nicht präzise bestimmbaren Einheiten (Motiv, Untermotiv, Phrase etc.) erschwert, für die in der Musiktheorie keine eindeutige Definition existiert.
Um die Längenverhältnisse zu messen unterteilt Boroda Melodien von Volksliedern sowie komponierter Musik auf Ebene der Motivtypen in die Einheiten 'mr-Segment' und 'F-Motiv' als dessen Konstituente.
Mr-Segmente sind eine Verknüpfung aufeinanderfolgender F-Motive, die durch gleiche rhythmische und metrische Gewichtungen verbunden sind. Die Einheit des F-Motivs kann als Gewichtung vorhergehender und nachfolgender Töne in einer Melodie gesehen werden. Mit Hilfe dieser Aufteilung lassen sich Aussagen über die Verteilung der Motivlänge treffen und selbstregulierende Mechanismen der Musik entschlüsseln.
Die Untersuchung zeigt: je größer die Anzahl der F-Motive in einem mr-Segment ist, desto kleiner sind diese F-Motive im Durchschnitt (Boroda und Altmann, 1991). Das Menzerath'sche-Gesetz kann damit auch für diesen Bereich als bestätigt gelten.
Literatur
- Altmann, Gabriel. 1980. Prolegomena to Menzerath’s Law. In: Grotjahn, R. (Hrsg.): Glottometrika 2. Bochum: Brockmeyer, 1 – 10. ISBN 3883391042
- Altmann, Gabriel. 1988. Wiederholungen in Texten. Bochum: Studienverlag Dr. N. Brockmeyer. ISBN 388339663X
- Altmann, Gabriel & Schwibbe, Michael H. & Kaumanns, Werner. 1989. Das Menzerathsche Gesetz in informationsverarbeitenden Systemen. Hildesheim, New York: G. Olms. ISBN 3487091445
- Boroda, M.G. & Altmann, G. 1991. Menzerath’s Law in Musical Texts. In: Boroda, M.G. (Hrsg.): Musikometrika 3. Bochum: Brockmeyer, 1 – 13. – ISBN 3883399051
- Fickermann, I. & Markner-Jäger, B. & Rothe, U. 1984. Wortlänge und Bedeutungskomplexität. In: Köhler, R. (Hrsg.) ; Boy, J. (Hrsg.): Glottometrika 6. Bochum: Brockmeyer, 115 – 126. ISBN 3883393762
- Gerlach, Rainer. 1982. Zur Überprüfung des Menzerath’schen Gesetzes im Bereich der Morphologie. In: Lehfeldt, U (Hrsg.): Glottometrika 4. Bochum: Brockmeyer, 95 – 102. ISBN 3883392502
- Geršić, Slavko & Altmann, Gabriel. 1980. Laut - Silbe - Wort und das Menzerathsche Gesetz. Frankfurter Phonetische Beiträge. In: Wodarz, H. W. (Hrsg.): Forum Phoneticum 21 Bd. 3. Hamburg: H. Buske, 115 – 123. ISBN 3883397776
- Hartmann, Peter & Faust, Manfred. 1983. Allgemeine Sprachwissenschaft, Sprachtypologie und Textlinguistik: Festschrift für Peter Hartmann. Tübingen: G. Narr. ISBN 3878082150
- Hřebíček, Luděk. 1989. Menzerath-Altmann’s law on the semantic level. In: Hřebíček, Luděk (Hrsg.): Glottometrika 11. Bochum: Brockmeyer, 47 – 56. ISBN 3883397776
- Hřebíček, Luděk. 1995. Text levels: Language constructs, constituents and the Menzerath-Altmann law. Trier: Wissenschaftlicher Verlag Trier. ISBN 388476179X
- Köhler, Reinhard. 1982. Das Menzerathsche Gesetz auf Satzebene. In: Lehfeldt, U (Hrsg.): Glottometrika 4. Bochum: Brockmeyer, 103 – 113. ISBN 3883392502.
- Köhler, Reinhard & Altmann, Gabriel & Piotrovskij, Raimond G. 2005. Quantitative Linguistik: Ein internationales Handbuch. Berlin, New York: M. de Gruyter, 659 - 688. ISBN 9783110155785.
- Menzerath, Paul. 1954. Phonetische Studien. Bd. 3: Die Architektonik des deutschen Wortschatzes. Bonn, Hannover, Stuttgart: Dümmler.
- Viëtor, Wilhelm & Meyer, Ernst A. 1921. Deutsches Aussprachewörterbuch. 3., durchges. Aufl. Leipzig: Reisland.